

LOS
10 MEJORES ALGORITMOS DE LISTAS ENLAZADAS
|
3.- Comparar dos cadenas representadas como listas vinculadas |
|
5.- Fusionar una lista vinculada con otra en posiciones alternas |
|
10.- Seleccione un nodo al azar de una lista de enlaces individuales |
&&&&&&&&&&
&&&&&&&
&&&
&
1.-
Dada una lista enlazada que está
ordenada, ¿cómo insertar de forma ordenada?
Dada
una lista de enlaces ordenados y un valor a insertar, escribe una función para
insertar el valor de forma ordenada.
Lista inicial

Después de la inserción del número 9:

Algoritmo:
Dejar
que la lista de enlaces de entrada se ordene en orden creciente.
1)
Si la lista de enlaces está vacía, entonces haga el nodo como
la cabeza y devolverla.
2)
Si el valor del nodo a insertar es menor
que el valor del nodo principal, entonces
inserte el nodo
en
el comienzo y hacer que la cabeza.
3)
En un bucle, encontrar el nodo apropiado después de
que el nodo de entrada (9) debe ser
insertado.
Para encontrar el nodo apropiado, comience
por la cabeza,
sigue moviéndote hasta que llegues a un nodo
GN (10 en
el siguiente diagrama) cuyo valor es mayor
que
el nodo de entrada. El nodo justo antes de
GN es el
nodo
apropiado (7).
4)
Inserte el nodo (9) después del nodo apropiado
(7) que se encuentra en el paso 3.
Implementación
en lenguaje C++:
#incluye <bits/stdc++.h>
usando namespace std;
/* Nodo de la lista de enlaces */
clase Nodo {
public:
datos int;
Nodo* siguiente;
};
Función /* para insertar un nuevo nodo
en una lista. Tenga en cuenta que este
La función espera que un puntero
head_ref ya que esto puede modificar el
jefe de la lista de enlaces de entrada
(similar a push())*/
void sortedInsert(Nodo** head_ref,
Nodo*
nuevo_nodo)
{
Nodo* actual;
/* Caso especial para la
cabeza */
si (*head_ref == NULL
||
(*head_ref)->datos
>=
nuevo_nodo->datos) {
new_node->next =
*head_ref;
*head_ref =
new_node;
}
más {
/* Localizar el nodo
antes de que el
punto de inserción */
current = *head_ref;
mientras que
(actual->siguiente != NULL
&& actual->siguiente->datos
< nuevo_nodo->datos) {
corriente =
corriente->siguiente;
}
new_node->next =
currentent->next;
actual->siguiente
= nuevo_nodo;
}
}
/* Una función de utilidad para
crear un nuevo nodo */
Nodo* nuevoNodo(int nuevo_datos)
{
/* asignar nodo */
Nodo* nuevo_nodo = nuevo
Nodo();
/* poner en los datos */
new_node->data =
new_data;
new_node->next =
NULL;
return new_node;
}
/* Función para imprimir la lista de enlaces */
void printList(Nodo* cabeza)
{
Nodo* temp = cabeza;
mientras que (temp !=
NULL) {
cout <<
temp->data << " ";
temp =
temp->siguiente;
}
}
/* Programa de control para probar la función de recuento*/
int main()
{
/* Empieza con la lista
vacía */
Nodo* cabeza = NULL;
Nodo* nuevo_nodo =
nuevoNodo(5);
sortedInsert(&head,
new_node);
new_node = newNode(10);
sortedInsert(&head,
new_node);
new_node = newNode(7);
sortedInsert(&head,
new_node);
new_node = newNode(3);
sortedInsert(&head,
new_node);
new_node = newNode(1);
sortedInsert(&head,
new_node);
new_node = newNode(9);
sortedInsert(&head,
new_node);
cout <<
"Creado lista de enlaces\n";
printList(head);
return 0;
}
Salida: Lista de enlaces creada: 1 3 5 7 9 10
Análisis
de la complejidad:
Complejidad
del tiempo: O(n).
Sólo
se necesita una travesía de la lista.
Espacio
Auxiliar: O(1).
No
se necesita espacio adicional.
Implementación
más corta usando punteros dobles:
Observe
que la línea inferior del código cambia la actual para tener la dirección del
siguiente puntero en un nodo.
current = &((*current)->next);
Además,
observe los siguientes comentarios.
/* Copia el valor en la dirección actual a
el siguiente puntero de new_node*/
new_node->next = *current;
/* Fijar el siguiente puntero del nodo
(usando su dirección)
después de lo cual se inserta un nuevo
nodo */
*corriente = nuevo_nodo;
Complejidad
del tiempo: O(n)
2.-
Suprimir un nodo determinado de la Lista de Enlaces con ciertas limitaciones
Si
se le da una lista de enlaces individuales, escriba una función para eliminar
un nodo determinado. Su función debe seguir las siguientes restricciones:
1)
Debe aceptar un puntero al nodo de inicio como primer parámetro y el nodo a
borrar como segundo parámetro, es decir, un puntero al nodo de cabecera no es
global.
2)
No debe devolver un puntero al nodo de cabecera.
3)
No debe aceptar puntero a puntero al nodo de cabeza.
Se
puede asumir que la Lista de enlaces nunca está vacía.
Deje
que el nombre de la función sea deleteNode(). En una implementación sencilla,
la función necesita modificar el puntero de la cabeza cuando el nodo a ser
eliminado es el primer nodo. Como se discutió en el post anterior, cuando una
función modifica el puntero de cabecera, la función debe usar uno de los
enfoques dados, no podemos usar ninguno de esos enfoques aquí.
Solución
Manejamos
explícitamente el caso cuando el nodo a ser eliminado es el primer nodo,
copiamos los datos del siguiente nodo a la cabeza y eliminamos el siguiente
nodo. Los casos en que un nodo eliminado no es el nodo de cabecera pueden
manejarse normalmente encontrando el nodo anterior y cambiando el siguiente del
nodo anterior. La siguiente es la implementación.
#include <bits/stdc++.h>
using namespace std;
class Node
{
public:
int data;
Node *next;
};
void deleteNode(Node *head, Node *n)
{
if(head == n)
{
if(head->next ==
NULL)
{
cout
<< "There is only one node." <<
"
The list can't be made empty ";
return;
}
head->data =
head->next->data;
n = head->next;
head->next =
head->next->next;
free(n);
return;
}
Node *prev = head;
while(prev->next != NULL &&
prev->next != n)
prev = prev->next;
if(prev->next == NULL)
{
cout << "\nGiven
node is not present in Linked List";
return;
}
prev->next = prev->next->next;
free(n);
return;
}
void push(Node **head_ref, int new_data)
{
Node *new_node = new Node();
new_node->data = new_data;
new_node->next = *head_ref;
*head_ref = new_node;
}
void printList(Node *head)
{
while(head!=NULL)
{
cout<<head->data<<"
";
head=head->next;
}
cout<<endl;
}
//Principal
int main()
{
Node *head = NULL;
push(&head,3);
push(&head,2);
push(&head,6);
push(&head,5);
push(&head,11);
push(&head,10);
push(&head,15);
push(&head,12);
cout<<"Given Linked List: ";
printList(head);
cout<<"\nDeleting node "<<
head->next->next->data<<" ";
deleteNode(head, head->next->next);
cout<<"\nModified Linked List:
";
printList(head);
cout<<"\nDeleting first node
";
deleteNode(head, head);
cout<<"\nModified Linked List:
";
printList(head);
return 0;
}
Salida: Dada la lista de enlaces: 12 15 10 11 5 6 2 3
Borrando el nodo 10:
Lista de enlaces modificada: 12 15 11 5 6 2 3
Borrar el primer nodo
Lista de enlaces modificada: 15 11 5 6 2 3
3.-
Comparar dos cadenas representadas como listas vinculadas
Dadas
dos cadenas, representadas como listas vinculadas (cada carácter es un nodo de
una lista vinculada). Escribir una función compare() que funcione de forma
similar a strcmp(), es decir, que devuelva 0 si ambas cadenas son iguales, 1 si
la primera lista enlazada es lexicográficamente mayor, y -1 si la segunda
cadena es lexicográficamente mayor.
Ejemplo:
Entrada:
lista1 = g->e->e->k->s->a
list2 = g->e->e->k->s->b
Salida:
-1
#include<bits/stdc++.h>
using namespace std;
struct Node
{
char c;
struct Node *next;
};
Node* newNode(char c)
{
Node *temp = new Node;
temp->c = c;
temp->next = NULL;
return temp;
};
int compare(Node *list1, Node *list2)
{
while (list1 && list2 &&
list1->c == list2->c)
{
list1 = list1->next;
list2 = list2->next;
}
if (list1 && list2)
return (list1->c >
list2->c)? 1: -1;
if (list1 && !list2) return 1;
if (list2 && !list1) return -1;
return 0;
}
// Principal
int main()
{
Node *list1 = newNode('g');
list1->next = newNode('e');
list1->next->next = newNode('e');
list1->next->next->next = newNode('k');
list1->next->next->next->next =
newNode('s');
list1->next->next->next->next->next
= newNode('b');
Node *list2 = newNode('g');
list2->next = newNode('e');
list2->next->next = newNode('e');
list2->next->next->next = newNode('k');
list2->next->next->next->next =
newNode('s');
list2->next->next->next->next->next
= newNode('a');
cout << compare(list1, list2);
return 0;
}
Salida: 1
4.-
Añadir dos números representados por listas vinculadas
Dados
dos números representados por dos listas enlazadas, escribe una función que
devuelva la lista de suma. La lista de suma es una representación de la suma de
dos números de entrada. No se permite modificar las listas. Tampoco se permite
usar espacio extra explícito (Pista: Usar Recursión).
Ejemplo
Entrada:
Primera lista: 5->6->3 // representa el
número 563
Segunda lista: 8->4->2 // representa el
número 842
Salida
La lista resultante: 1->4->0->5 //
representa el número 1405
Hemos
discutido aquí una solución que es para las listas enlazadas donde un dígito
menos significativo es el primer nodo de las listas y el dígito más
significativo es el último nodo. En este problema, el nodo más significativo es
el primer nodo y el dígito menos significativo es el último nodo y no se nos
permite modificar las listas. La recursividad se usa aquí para calcular la suma
de derecha a izquierda.
A
continuación, los pasos a seguir.
1)
Calcular los tamaños de dos listas enlazadas.
2)
Si los tamaños son iguales, entonces calcula la suma usando la recursividad.
Mantener todos los nodos en la pila de llamadas de recursividad hasta el nodo
más a la derecha, calcular la suma de los nodos más a la derecha y llevarlos al
lado izquierdo.
3)
Si el tamaño no es el mismo, entonces siga los siguientes pasos:
....a)
Calcular la diferencia de tamaños de dos listas vinculadas. Dejar que la
diferencia se difunda
....b)
Mueve los nodos de difusión hacia adelante en la lista de enlaces más grande.
Ahora usa el paso 2 para calcular la suma de la lista más pequeña y la sublista
derecha (del mismo tamaño) de una lista más grande. Además, almacena el
transporte de esta suma.
....c)
Calcule la suma del carry (calculado en el paso anterior) con el resto de la
sublista izquierda de una lista mayor. Los nodos de esta suma se añaden al
principio de la lista de suma obtenida en el paso anterior.
#include <bits/stdc++.h>
using namespace std;
class Node
{
public:
int data;
Node* next;
};
typedef Node node;
void push(Node** head_ref, int new_data)
{
Node* new_node = new Node[(sizeof(Node))];
new_node->data = new_data;
new_node->next = (*head_ref);
(*head_ref) = new_node;
}
void printList(Node *node)
{
while (node != NULL)
{
cout<<node->data<<"
";
node = node->next;
}
cout<<endl;
}
void swapPointer( Node** a, Node** b )
{
node* t = *a;
*a = *b;
*b = t;
}
int getSize(Node *node)
{
int size = 0;
while (node != NULL)
{
node = node->next;
size++;
}
return size;
}
node* addSameSize(Node* head1, Node* head2, int* carry)
{
if (head1 == NULL) return NULL;
int sum;
Node* result = new Node[(sizeof(Node))];
result->next = addSameSize(head1->next,
head2->next, carry);
sum = head1->data + head2->data +
*carry;
*carry = sum / 10;
sum = sum % 10;
result->data = sum;
return result;
}
void addCarryToRemaining(Node* head1, Node* cur,
int*
carry, Node** result)
{
int sum;
if (head1 != cur)
{
addCarryToRemaining(head1->next,
cur, carry, result);
sum = head1->data +
*carry;
*carry = sum/10;
sum %= 10;
push(result, sum);
}
}
void addList(Node* head1, Node* head2, Node** result)
{
Node *cur;
if (head1 == NULL)
{
*result = head2;
return;
}
else if (head2 == NULL)
{
*result = head1;
return;
}
int size1 = getSize(head1);
int size2 = getSize(head2) ;
int carry = 0;
if (size1 == size2) *result
= addSameSize(head1, head2, &carry);
else
{
int diff = abs(size1 -
size2);
if (size1 < size2)
swapPointer(&head1, &head2);
for (cur = head1; diff--;
cur = cur->next);
*result = addSameSize(cur,
head2, &carry);
addCarryToRemaining(head1,
cur, &carry, result);
}
if (carry) push(result,
carry);
}
// Principal
int main()
{
Node *head1 = NULL, *head2 = NULL, *result =
NULL;
int arr1[] = {9, 9, 9};
int arr2[] = {1, 8};
int size1 = sizeof(arr1) / sizeof(arr1[0]);
int size2 = sizeof(arr2) / sizeof(arr2[0]);
int i;
for (i = size1-1; i >= 0; --i)
push(&head1, arr1[i]);
for (i = size2-1; i >= 0; --i)
push(&head2, arr2[i]);
addList(head1, head2, &result);
printList(result);
return 0;
}
Salida: 1 0
1 7
Complejidad:
O(m+n)
5.-
Fusionar una lista vinculada con otra en posiciones alternas
Dadas
dos listas vinculadas, inserte los nodos de la segunda lista en la primera
lista en posiciones alternas de la primera lista.
Por
ejemplo, si la primera lista es 5->7->17->13->11 y la segunda es
12->10->2->4->6, la primera lista debe convertirse en
5->12->7->10->17->2->13->4->11->6 y la segunda lista
debe quedar vacía. Los nodos de la segunda lista sólo deben ser insertados
cuando haya posiciones disponibles. Por ejemplo, si la primera lista es
1->2->3 y la segunda lista es 4->5->6->7->8, entonces la
primera lista debe convertirse en 1->4->2->5->3->6 y la segunda
lista en 7->8.
No
se permite el uso de espacio adicional (no se permite crear nodos adicionales),
es decir, la inserción debe hacerse en el lugar. La complejidad de tiempo
esperada es O(n) donde n es el número de nodos en la primera lista.
La
idea es ejecutar un bucle mientras haya posiciones disponibles en el primer
bucle e insertar nodos de la segunda lista cambiando los punteros. A
continuación se muestran las implementaciones de este enfoque.
#include <bits/stdc++.h>
using namespace std;
class Node
{
public:
int data;
Node *next;
};
void push(Node ** head_ref, int new_data)
{
Node* new_node = new Node();
new_node->data = new_data;
new_node->next = (*head_ref);
(*head_ref) = new_node;
}
void printList(Node *head)
{
Node *temp = head;
while (temp != NULL)
{
cout<<temp->data<<"
";
temp = temp->next;
}
cout<<endl;
}
void merge(Node *p, Node **q)
{
Node *p_curr = p, *q_curr = *q;
Node *p_next, *q_next;
while (p_curr != NULL && q_curr !=
NULL)
{
p_next =
p_curr->next;
q_next =
q_curr->next;
q_curr->next = p_next;
// Change next pointer of q_curr
p_curr->next = q_curr;
// Change next pointer of p_curr
p_curr = p_next;
q_curr = q_next;
}
*q = q_curr; // Update head pointer of second
list
}
// Driver code
int main()
{
Node *p = NULL, *q = NULL;
push(&p, 3);
push(&p, 2);
push(&p, 1);
cout<<"First Linked List:\n";
printList(p);
push(&q, 8);
push(&q, 7);
push(&q, 6);
push(&q, 5);
push(&q, 4);
cout<<"Second Linked
List:\n";
printList(q);
merge(p, &q);
cout<<"Modified First Linked
List:\n";
printList(p);
cout<<"Modified Second Linked
List:\n";
printList(q);
return 0;
}
Salida: Primera lista de enlaces:
1 2 3
Segunda lista de enlaces:
4 5 6 7 8
Modificada la primera lista de enlaces:
1 4 2 5 3 6
Segunda lista de enlaces modificada:
7 8
6.-
Invertir una lista en grupos de un tamaño determinado
Dada
una lista enlazada, escriba una función para invertir cada nodo k (donde k es
una entrada a la función).
Ejemplo:
Entrada:
1->2->3->4->5->6->7->8->NULO, K = 3
Salida:
3->2->1->6->5->4->8->7->NULL
Invierte
la primera sub-lista de tamaño k. Mientras se invierte, manténgase al tanto del
siguiente nodo y del anterior. Deje que el puntero al siguiente nodo sea
siguiente y el puntero al nodo anterior sea anterior. Vea este post para
invertir una lista enlazada.
head->next
= reverse(next, k) ( Llama recurrentemente al resto de la lista y enlaza las
dos sub-listas )
Return
prev ( prev se convierte en el nuevo principal de la lista)
#include <bits/stdc++.h>
using namespace std;
class Node
{
public:
int data;
Node* next;
};
/* Invierte la lista de enlaces en grupos
de tamaño k y devuelve el puntero
al nuevo nodo principal. */
Node *reverse (Node *head, int k)
{
Node* current = head;
Node* next = NULL;
Node* prev = NULL;
int count = 0;
/* invertir los primeros nodos k de la lista de enlaces
*/
while (current != NULL && count <
k)
{
next =
current->next;
current->next =
prev;
prev = current;
current = next;
count++;
}
/* lo siguiente es ahora un puntero al nodo
(k+1)th
Recurrir a la lista a partir de
la corriente.
Y hacer el resto de la lista como
el siguiente del primer nodo
*/
if (next != NULL) head->next =
reverse(next, k);
return prev;
}
void push(Node** head_ref, int new_data)
{
Node* new_node = new Node();
new_node->data = new_data;
new_node->next =
(*head_ref);
(*head_ref) = new_node;
}
void printList(Node *node)
{
while (node != NULL)
{
cout<<node->data<<"
";
node = node->next;
}
}
//Principal
int main()
{
Node* head = NULL;
push(&head, 9);
push(&head, 8);
push(&head, 7);
push(&head, 6);
push(&head, 5);
push(&head, 4);
push(&head, 3);
push(&head, 2);
push(&head, 1);
cout<<" Dada la lista
de enlaces\n";
printList(head);
head = reverse(head, 3);
cout<<"\n Lista
invertida \n";
printList(head);
return(0);
}
Salida:
Dada la lista de enlaces
1 2 3 4 5 6 7 8 9
Lista invertida
3 2 1 6 5 4 9 8 7
Análisis de la complejidad:
Complejidad del tiempo: O(n).
La travesía de la lista se hace una sola vez y tiene 'n' elementos.
Espacio Auxiliar: O(1).
No se utiliza la estructura de datos para almacenar valores.
7.-
Unión e intersección de dos listas vinculadas
Dadas
dos Listas Vinculadas, crear listas de unión e intersección que contengan la
unión e intersección de los elementos presentes en las listas dadas. El orden
de los elementos en las listas de salida no importa.
Ejemplo:
Entrada:
Lista1: 10->15->4->20
lsit2: 8->4->2->10
Método
1 (Usar el método de fusión)
En
este método, los algoritmos para la Unión e Intersección son muy similares.
Primero, clasificamos las listas dadas, luego atravesamos las listas
clasificadas para obtener unión e intersección.
Los
siguientes son los pasos a seguir para obtener las listas de unión e
intersección.
Ordenar
la primera lista de unión usando el orden de unión. Este paso lleva O(mLogm)
tiempo. Consulte este post para conocer los detalles de este paso.
Ordenar
la segunda Lista Enlazada usando el orden de fusión. Este paso lleva O(nLogn)
tiempo. Consulte esta entrada para obtener más información sobre este paso.
Escanea
linealmente ambas listas ordenadas para obtener la unión y la intersección.
Este paso lleva O(m + n) tiempo. Este paso puede ser implementado usando el mismo
algoritmo que el de las listas ordenadas que se discute aquí.
La
complejidad temporal de este método es O(mLogm + nLogn) que es mejor que la
complejidad temporal del método 1.
Método
2 (Usar Hashing)
Unión
(lista1, lista2)
Inicializa
la lista de resultados como NULL y crea una tabla hash vacía. Recorrer ambas
listas una por una, para cada elemento visitado, buscar el elemento en la tabla
hash. Si el elemento no está presente, entonces inserte el elemento en la lista
de resultados. Si el elemento está presente, entonces ignóralo.
Intersección
(lista1, lista2)
Inicializa
la lista de resultados como NULL y crea una tabla hash vacía. Recorrer la
lista1. Para cada elemento que se visita en la lista1, inserte el elemento en
la tabla hash. Recorrer lista2, para cada elemento que se visita en lista2,
buscar el elemento en la tabla hash. Si el elemento está presente, entonces
inserte el elemento en la lista de resultados. Si el elemento no está presente,
entonces ignórelo.
Los
dos métodos anteriores suponen que no hay duplicados.
import java.util.HashMap;
import java.util.HashSet;
class LinkedList {
Node head;
class Node {
int data;
Node next;
Node(int d)
{
data
= d;
next
= null;
}
}
void printList()
{
Node temp = head;
while (temp != null) {
System.out.print(temp.data
+ " ");
temp
= temp.next;
}
System.out.println();
}
void push(int new_data)
{
Node new_node = new
Node(new_data);
new_node.next = head;
head = new_node;
}
public void append(int new_data)
{
if (this.head == null) {
Node
n = new Node(new_data);
this.head
= n;
return;
}
Node n1 = this.head;
Node n2 = new
Node(new_data);
while (n1.next != null) {
n1
= n1.next;
}
n1.next = n2;
n2.next = null;
}
/* Una función de utilidad que devuelve la verdad
si los datos son
presente en la lista de enlaces,
si no, devuelve falso
*/
boolean isPresent(Node head, int data)
{
Node t = head;
while (t != null) {
if
(t.data == data)
return
true;
t =
t.next;
}
return false;
}
LinkedList getIntersection(Node head1, Node head2)
{
HashSet<Integer> hset
= new HashSet<>();
Node n1 = head1;
Node n2 = head2;
LinkedList result = new
LinkedList();
// loop stores all the
elements of list1 in hset
while (n1 != null) {
if
(hset.contains(n1.data)) {
hset.add(n1.data);
}
else
{
hset.add(n1.data);
}
n1
= n1.next;
}
while (n2 != null) {
if
(hset.contains(n2.data)) {
result.push(n2.data);
}
n2
= n2.next;
}
return result;
}
LinkedList getUnion(Node head1, Node head2)
{
HashMap<Integer,
Integer> hmap = new HashMap<>();
Node n1 = head1;
Node n2 = head2;
LinkedList result = new
LinkedList();
while (n1 != null) {
if
(hmap.containsKey(n1.data)) {
int
val = hmap.get(n1.data);
hmap.put(n1.data,
val + 1);
}
else
{
hmap.put(n1.data,
1);
}
n1
= n1.next;
}
while (n2 != null) {
if
(hmap.containsKey(n2.data)) {
int
val = hmap.get(n2.data);
hmap.put(n2.data,
val + 1);
}
else
{
hmap.put(n2.data,
1);
}
n2
= n2.next;
}
for (int a : hmap.keySet())
{
result.append(a);
}
return result;
}
public static void main(String args[])
{
LinkedList llist1 = new
LinkedList();
LinkedList llist2 = new
LinkedList();
LinkedList union = new
LinkedList();
LinkedList intersection =
new LinkedList();
llist1.push(20);
llist1.push(4);
llist1.push(15);
llist1.push(10);
llist2.push(10);
llist2.push(2);
llist2.push(4);
llist2.push(8);
intersection
= intersection.getIntersection(llist1.head,
llist2.head);
union =
union.getUnion(llist1.head, llist2.head);
System.out.println("La
primera lista es ");
llist1.printList();
System.out.println("La
segunda lista es ");
llist2.printList();
System.out.println("La
lista de intersección es ");
intersection.printList();
System.out.println("La
lista de la Unión es ");
union.printList();
}
}
Salida:
La primera lista es
10 15 4 20
La segunda lista es
8 4 2 10
La lista de intersección es
10 4
La lista de la Unión es
2 4 20 8 10 15
Análisis de la
complejidad:
Complejidad temporal: O(m+n).
Aquí 'm' y 'n' son el número de elementos presentes en la primera y segunda
lista respectivamente.
Para la unión: Recorrer ambas listas, almacenar los elementos en el mapa
Hash- y actualizar el recuento respectivo.
Para la intersección: Primero atraviesa la lista 1, almacena sus elementos
en Hash-map y luego para cada elemento de la lista 2 comprueba si ya está
presente en el mapa. Esto lleva O(1) tiempo.
Espacio auxiliar:O(m+n).
Uso de la estructura de datos de Hash-map para almacenar valores.
8.-
Detectar y eliminar el bucle en una lista de enlaces
Escribe
una función detectAndRemoveLoop() que compruebe si una Lista Enlazada dada
contiene un bucle y si el bucle está presente entonces lo elimina y devuelve
verdadero. Si la lista no contiene bucle entonces devuelve false. El siguiente
diagrama muestra una lista enlazada con un bucle. detectAndRemoveLoop() debe
cambiar la lista de abajo a 1->2->3->4->5->NULL.
Sabemos
que el algoritmo de detección del Ciclo de Floyd termina cuando los punteros
rápidos y lentos se encuentran en un punto común. También sabemos que este
punto común es uno de los nodos de bucle (2 o 3 o 4 o 5 en el diagrama
anterior). Guarda la dirección de esto en una variable de puntero, digamos
ptr2. Después de eso, comienza desde la cabecera de la Lista de Enlaces y
comprueba uno por uno si los nodos son alcanzables desde ptr2. Siempre que
encontramos un nodo que es alcanzable, sabemos que este nodo es el nodo de
inicio del bucle en Linked List y podemos obtener el puntero al anterior de este
nodo.
#include <bits/stdc++.h>
using namespace std;
struct Node {
int data;
struct Node* next;
};
int detectAndRemoveLoop(struct Node* list)
{
struct Node *slow_p = list, *fast_p = list;
while (slow_p && fast_p && fast_p->next)
{
slow_p = slow_p->next;
fast_p =
fast_p->next->next;
if (slow_p == fast_p) {
removeLoop(slow_p,
list);
return
1;
}
}
return 0;
}
/* Función para eliminar el bucle.
loop_node --> Apuntador a uno de
los nodos del bucle
head --> Apuntador al nodo de
inicio de la lista de enlaces
*/
void removeLoop(struct Node* loop_node, struct Node* head)
{
struct Node* ptr1;
struct Node* ptr2;
/* Ponga un puntero al principio de la Lista de
Enlaces y
moverlo uno por uno para
encontrar el primer nodo que es
parte de la Lista de Enlaces
*/
ptr1 = head;
while (1) {
ptr2 = loop_node;
while (ptr2->next != loop_node
&& ptr2->next != ptr1)
ptr2
= ptr2->next;
if (ptr2->next == ptr1)
break;
ptr1 = ptr1->next;
}
ptr2->next = NULL;
}
void printList(struct Node* node)
{
while (node != NULL) {
cout << node->data
<< " ";
node = node->next;
}
}
struct Node* newNode(int key)
{
struct Node* temp = new Node();
temp->data = key;
temp->next = NULL;
return temp;
}
int main()
{
struct Node* head = newNode(50);
head->next = newNode(20);
head->next->next = newNode(15);
head->next->next->next = newNode(4);
head->next->next->next->next =
newNode(10);
head->next->next->next->next->next =
head->next->next;
detectAndRemoveLoop(head);
cout << "Linked List after removing
loop" << endl;
printList(head);
return 0;
}
Salida: 50 20
15 4 10
9.-
Fusionar y ordenar listas vinculadas
A menudo se
prefiere la clasificación por fusión para clasificar una lista de enlaces. El
lento rendimiento de acceso aleatorio de una lista enlazada hace que algunos
otros algoritmos (como el quicksort) funcionen mal, y otros (como el heapsort)
son completamente imposibles.
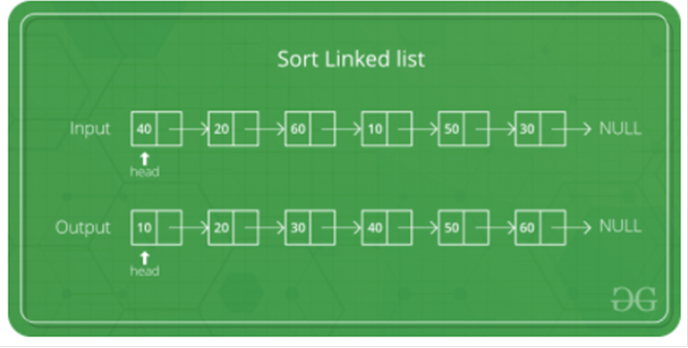
Dejemos que
head sea el primer nodo de la lista enlazada que se ordene y que headRef sea el
puntero a head. Nótese que necesitamos una referencia a head en MergeSort() ya
que la siguiente implementación cambia los siguientes enlaces para ordenar las
listas enlazadas (no los datos en los nodos), por lo que el nodo head tiene que
ser cambiado si los datos en la cabecera original no son el valor más pequeño
de la lista enlazada.
MergeSort(headRef)
1) Si la
cabeza es NULL o sólo hay un elemento en la Lista de Enlaces
...y luego regresar.
2) Si no,
divide la lista en dos mitades.
FrontBackSplit(cabeza, &a, &b);
/* a y b son dos mitades */
3) Ordena las
dos mitades a y b.
FusionarSorpresa(a);
FusionarSer(b);
4) Fusionar
las clasificadas a y b (usando SortedMerge() discutido aquí)
y actualizar el puntero de la cabeza usando
el headRef.
*headRef = SortedMerge(a, b);
#include <bits/stdc++.h>
using namespace std;
class Node {
public:
int data;
Node* next;
};
Node* SortedMerge(Node* a, Node* b);
void FrontBackSplit(Node* source,
Node**
frontRef, Node** backRef);
void MergeSort(Node** headRef)
{
Node* head = *headRef;
Node* a;
Node* b;
if ((head == NULL) || (head->next == NULL)) {
return;
}
FrontBackSplit(head, &a, &b);
MergeSort(&a);
MergeSort(&b);
*headRef = SortedMerge(a, b);
}
Node* SortedMerge(Node* a, Node* b)
{
Node* result = NULL;
if (a == NULL) return
(b);
else if (b == NULL)
return (a);
if (a->data <= b->data) {
result = a;
result->next =
SortedMerge(a->next, b);
}
else {
result = b;
result->next =
SortedMerge(a, b->next);
}
return (result);
}
/* Dividir los nodos de la lista dada en mitades delanteras y
traseras,
y devolver las dos listas
utilizando los parámetros de referencia.
Si la longitud es extraña, el
nodo extra debe ir en la lista principal.
Utiliza la estrategia de puntero
rápido/lento
. */
void FrontBackSplit(Node* source,
Node**
frontRef, Node** backRef)
{
Node* fast;
Node* slow;
slow = source;
fast = source->next;
while (fast != NULL) {
fast = fast->next;
if (fast != NULL) {
slow
= slow->next;
fast
= fast->next;
}
}
*frontRef = source;
*backRef = slow->next;
slow->next = NULL;
}
void printList(Node* node)
{
while (node != NULL) {
cout << node->data
<< " ";
node = node->next;
}
}
void push(Node** head_ref, int new_data)
{
Node* new_node = new Node();
new_node->data = new_data;
new_node->next = (*head_ref);
(*head_ref) = new_node;
}
int main()
{
/* Start with the empty list */
Node* res = NULL;
Node* a = NULL;
push(&a, 15);
push(&a, 10);
push(&a, 5);
push(&a, 20);
push(&a, 3);
push(&a, 2);
MergeSort(&a);
cout << "Sorted Linked List is:
\n";
printList(a);
return 0;
}
Salida: 2 3
5 10 15
20
Complejidad: O(n Log n)
10.-
Seleccione un nodo al azar de una lista de enlaces individuales
Dada una lista
vinculada individualmente, seleccione un nodo al azar de la lista vinculada (la
probabilidad de elegir un nodo debe ser de 1/N si hay nodos en la lista). Se le
da un generador de números aleatorios.
A continuación
se presenta una solución sencilla
1) Cuente el
número de nodos atravesando la lista.
2) Vuelva a
recorrer la lista y seleccione cada nodo con probabilidad 1/N. La selección
puede hacerse generando un número aleatorio de 0 a N-i para el nodo i'th, y
seleccionando el nodo i'th sólo si el número generado es igual a 0 (o cualquier
otro número fijo de 0 a N-i).
Obtenemos
probabilidades uniformes con los esquemas anteriores.
i = 1,
probabilidad de seleccionar el primer nodo = 1/N
i = 2,
probabilidad de seleccionar el segundo nodo =
[probabilidad de que el
primer nodo no esté seleccionado] *
[probabilidad de que el
segundo nodo sea seleccionado]
= ((N-1)/N)* 1/(N-1)
= 1/N
De manera
similar, las probabilidades de que otros seleccionen otros nodos es de 1/N
La solución
anterior requiere dos espacios de lista enlazados.
¿Cómo
seleccionar un nodo al azar con una sola travesía permitida?
La idea es
usar el "Reservoir Sampling". Los siguientes son los pasos. Esta es
una versión más simple del Reservoir Sampling ya que necesitamos seleccionar
sólo una tecla en lugar de las teclas k.
(1)
Inicializar el resultado como primer nodo
resultado = cabeza-> tecla
(2)
Inicializar n = 2
(3) Ahora, uno
por uno, consideren todos los nodos desde el segundo nodo en adelante.
(3.a) Generar un número aleatorio de 0 a
n-1.
Dejemos que el número aleatorio
generado sea j.
(3.b) Si j es igual a 0 (podríamos elegir
otro número fijo
entre 0 y n-1), y luego reemplazar el
resultado con el nodo actual.
(3.c) n = n+1
(3.d) corriente = corriente->siguiente
#include<stdio.h>
#include<stdlib.h>
#include <time.h>
#include<iostream>
using namespace std;
class Node
{
public:
int key;
Node* next;
void printRandom(Node*);
void push(Node**, int);
};
void Node::printRandom(Node *head)
{
// IF list is empty
if (head == NULL)
return;
srand(time(NULL));
int result = head->key;
Node *current = head;
int n;
for (n = 2; current != NULL; n++)
{
if (rand() % n
== 0)
result = current->key;
current = current->next;
}
cout<<"Randomly selected key is
\n"<< result;
}
Node* newNode(int new_key)
{
Node* new_node = (Node*) malloc(sizeof( Node));
new_node->key = new_key;
new_node->next = NULL;
return new_node;
}
void Node:: push(Node** head_ref, int new_key)
{
Node* new_node = new Node;
new_node->key = new_key;
new_node->next = (*head_ref);
(*head_ref) = new_node;
}
int main()
{
Node n1;
Node *head = NULL;
n1.push(&head, 5);
n1.push(&head, 20);
n1.push(&head, 4);
n1.push(&head, 3);
n1.push(&head, 30);
n1.printRandom(head);
return 0;
}
Tener en
cuenta que el programa anterior se basa en el resultado de una función
aleatoria y puede producir un resultado diferente.
¿Cómo funciona
esto?
Deja que haya
un total de nodos en la lista. Es más fácil de entender desde el último nodo.
La
probabilidad de que el último nodo sea el resultado simplemente 1/N [Para el
último o N'th nodo, generamos un número aleatorio entre 0 y N-1 y hacemos el
último nodo como resultado si el número generado es 0 (o cualquier otro número
fijo)
La
probabilidad de que el penúltimo nodo sea el resultado también debería ser 1/N.
La
probabilidad de que el penúltimo nodo sea el resultado
= [Probabilidad de que el penúltimo
nodo sustituya al resultado] X
[Probabilidad de que el último nodo
no reemplace el resultado]
= [1 / (N-1)] * [(N-1)/N]
= 1/N
De manera
similar podemos mostrar la probabilidad para el 3er último nodo y otros nodos.
&&&&&&&&&&&
&&&&&&&&
&&&
&